写一小段测试代码来测试前面写的数据防爬程序,不停访问某个页面:
实际上REMOTE_HOST是服务器根据自己DNS解析得到的,但我这里测试它能否直接在header中伪装:
import httplib
import sys
import datetime
import random
headers = {'User-Agent': 'Googlebot/2.1 (+http://www.google.com/bot.html)',
'Connection': 'keep-alive',
'REMOTE_HOST': 'www.googlebot.com'}
while True:
conn = httplib.HTTPConnection("www.fachun.net")
conn.request(method='GET', url='/album/972-Nine%20Objects%20Of%20Desire/?' + str(random.random()), headers=headers)
response = conn.getresponse()
print response.status, datetime.datetime.now()
if response.status == 403:
print 'forbidden error, exit'
sys.exit(-1)
conn.close()
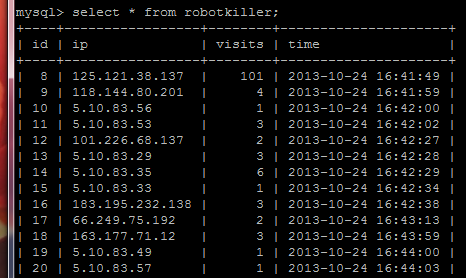
数据库中的内容:
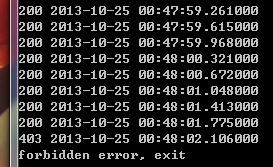
在浏览器中打开一个页面,将出现:

经过测试,我决定将10分钟100次请求限制到更小的60次请求。
博主的文章都很实用,我也用django很久了,也对爬虫感兴趣