下午偶然发现有IP来访异常,如下图, 前面6个IP都被封过了:
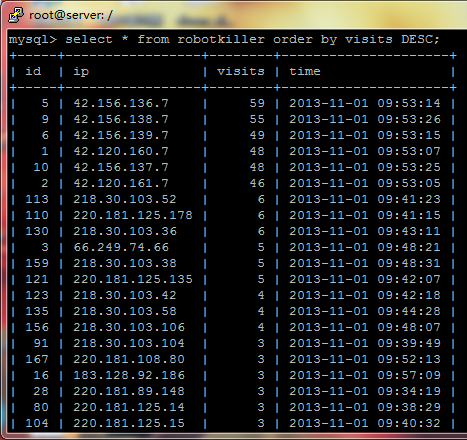
经查询,前面几个IP是阿里云的。
在apache的日志中查看对应IP的记录,发现user-agent是YisouSpider,属于阿里一个叫“一搜”的产品。
它是做电影搜索的,但我的网站: http://www.fachun.net只提供音乐内容。
这些爬虫的访问不会给我带来任何好处,还占用系统资源和带宽。可以禁止它抓取页面。
在robots.txt中编辑:
User-agent: YisouSpider Disallow: /
然后到urls.py中添加对应的url:
url(r'^robots.txt$', TemplateView.as_view(template_name="robots.txt", content_type='text/plain; charset=UTF-8')),
重启apache即可。 http://www.fachun.net/robots.txt
实际上,更加自律的爬虫,一般都是晚上服务器空闲的时候,才会来大量抓取内容。
一搜的爬虫似乎应该更加自律一点。
说的好,自律—业界良心!
是的,一搜很恶心
rel=”nofollow” 还是被yisou抓了。。
为啥我搜YisouSpider,查出来的是叫“神马搜索”。
写robots.txt没用的,我仔细查了access.log,
1、这货就从没访问过robots.txt
2、我的robots.txt写的也是Disallow: /
完全不管用